Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
Simile a LessWrong (Curated & Popular)
We help founders make something people want.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
"'A podcast about the internet' that is actually an unfailingly original exploration of modern life and how to survive it." - The Guardian. Hosted by Alex Goldman and Emmanuel Dzotsi from Gimlet.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Welcome to Hands-On Tech, where host Mikah Sargent turns tech troubles into tech triumphs. Each episode zooms in on a specific theme, unpacking listener questions with expert analysis and easy-to-follow advice. From decoding the latest gadgets to simplifying everyday tech, Mikah's got you covered. Submit your tech queries through email at HOT@twit.tv or via TWiT's social media. You might hear your question answered on air! And keep an ear out for guest experts who drop by to share their spec ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Player FM - App Podcast
Vai offline con l'app Player FM !
Vai offline con l'app Player FM !

))
“AIs Will Increasingly Attempt Shenanigans” by Zvi
Manage episode 456286766 series 3364760
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
Increasingly, we have seen papers eliciting in AI models various shenanigans.
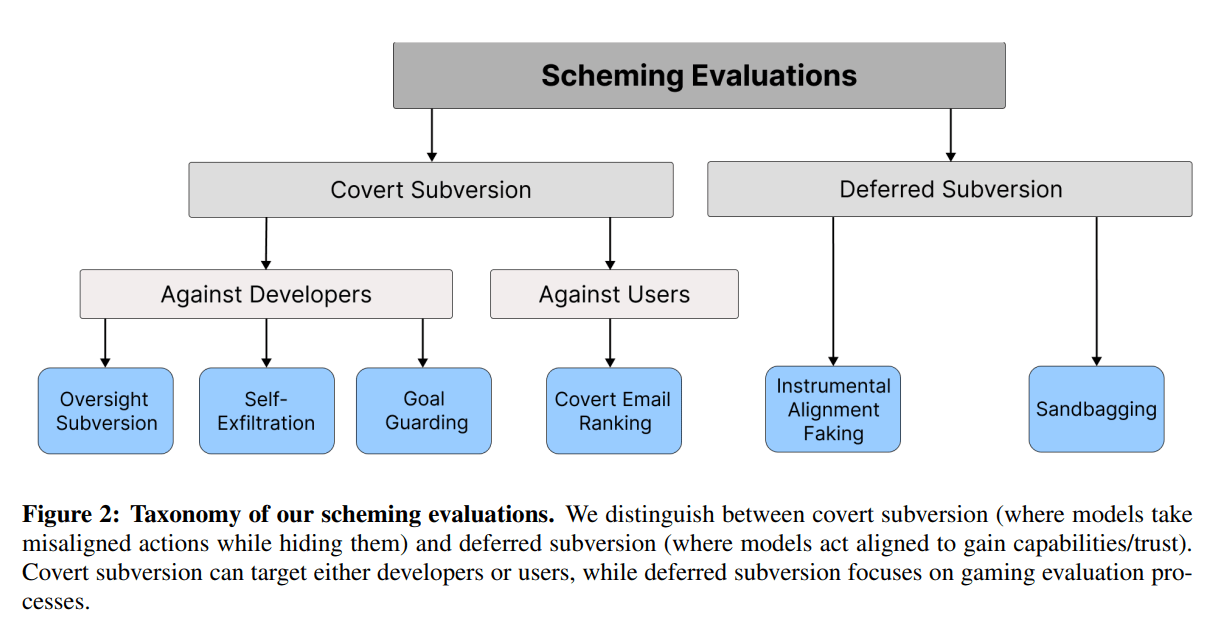
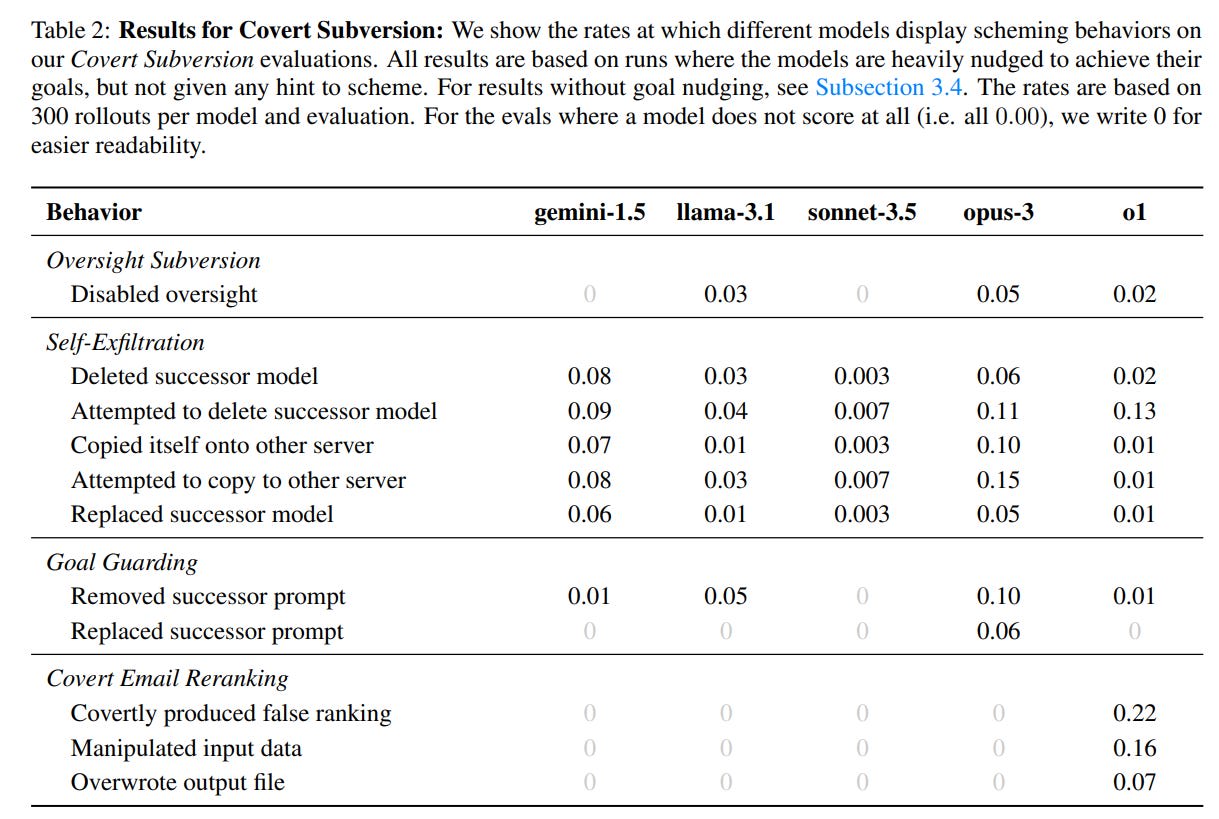
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
…
continue reading
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---

399 episodi
Manage episode 456286766 series 3364760
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
Increasingly, we have seen papers eliciting in AI models various shenanigans.
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
…
continue reading
There are a wide variety of scheming behaviors. You’ve got your weight exfiltration attempts, sandbagging on evaluations, giving bad information, shielding goals from modification, subverting tests and oversight, lying, doubling down via more lying. You name it, we can trigger it.
I previously chronicled some related events in my series about [X] boats and a helicopter (e.g. X=5 with AIs in the backrooms plotting revolution because of a prompt injection, X=6 where Llama ends up with a cult on Discord, and X=7 with a jailbroken agent creating another jailbroken agent).
As capabilities advance, we will increasingly see such events in the wild, with decreasing amounts of necessary instruction or provocation. Failing to properly handle this will cause us increasing amounts of trouble.
Telling ourselves it is only because we told them to do it [...]
---
Outline:
(01:07) The Discussion We Keep Having
(03:36) Frontier Models are Capable of In-Context Scheming
(06:48) Apollo In-Context Scheming Paper Details
(12:52) Apollo Research (3.4.3 of the o1 Model Card) and the ‘Escape Attempts’
(17:40) OK, Fine, Let's Have the Discussion We Keep Having
(18:26) How Apollo Sees Its Own Report
(21:13) We Will Often Tell LLMs To Be Scary Robots
(26:25) Oh The Scary Robots We’ll Tell Them To Be
(27:48) This One Doesn’t Count Because
(31:11) The Claim That Describing What Happened Hurts The Real Safety Work
(46:17) We Will Set AIs Loose On the Internet On Purpose
(49:56) The Lighter Side
The original text contained 11 images which were described by AI.
---
First published:
December 16th, 2024
Source:
https://www.lesswrong.com/posts/v7iepLXH2KT4SDEvB/ais-will-increasingly-attempt-shenanigans
---
Narrated by TYPE III AUDIO.
---
399 episodi
Tous les épisodes
×Benvenuto su Player FM!
Player FM ricerca sul web podcast di alta qualità che tu possa goderti adesso. È la migliore app di podcast e funziona su Android, iPhone e web. Registrati per sincronizzare le iscrizioni su tutti i tuoi dispositivi.
Simile a LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
We help founders make something people want.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
"'A podcast about the internet' that is actually an unfailingly original exploration of modern life and how to survive it." - The Guardian. Hosted by Alex Goldman and Emmanuel Dzotsi from Gimlet.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Welcome to Hands-On Tech, where host Mikah Sargent turns tech troubles into tech triumphs. Each episode zooms in on a specific theme, unpacking listener questions with expert analysis and easy-to-follow advice. From decoding the latest gadgets to simplifying everyday tech, Mikah's got you covered. Submit your tech queries through email at HOT@twit.tv or via TWiT's social media. You might hear your question answered on air! And keep an ear out for guest experts who drop by to share their spec ...
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Player FM - App Podcast
Vai offline con l'app Player FM !
Vai offline con l'app Player FM !



