The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
Simile a LessWrong (Curated & Popular)
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Redefining AI is a Three-Time Award-Winning Tech Podcast that cuts through the noise! Join Lauren Hawker Zafer, Chief Operating Officer at Squirro and Stevie Silver Award–winning creator, for a bold, thought-provoking exploration of artificial intelligence. Celebrated as intellectually rigorous, globally relevant, and truly unique, the show examines how AI shapes us socially, psychologically, and even physiologically. Each episode brings together leading academics, authors, executives, and i ...
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Audio home of The Jimquisition, featuring its lovely little podcast, Podquisition - starring Jim Sterling, Laura Kate, and Conrad Zimmerman!
…
continue reading
Investor Shayle Kann is asking big questions about how to decarbonize the planet: How cheap can clean energy get? Will artificial intelligence speed up climate solutions? Where is the smart money going into climate technologies? Every week on Catalyst, Shayle explains the world of climate tech with prominent experts, investors, researchers, and executives. Produced by Latitude Media.
…
continue reading
Player FM - App Podcast
Vai offline con l'app Player FM !
Vai offline con l'app Player FM !

))
“METR: Measuring AI Ability to Complete Long Tasks” by Zach Stein-Perlman
Manage episode 475707851 series 3364760
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
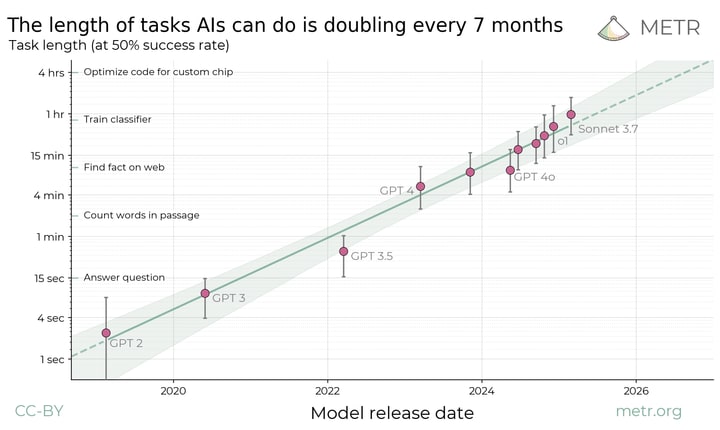
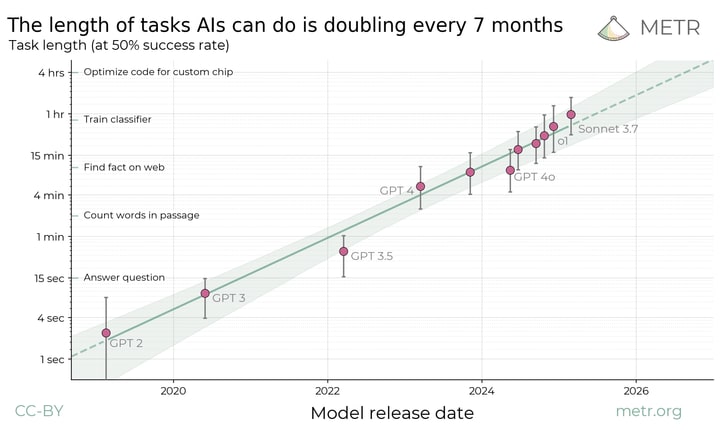
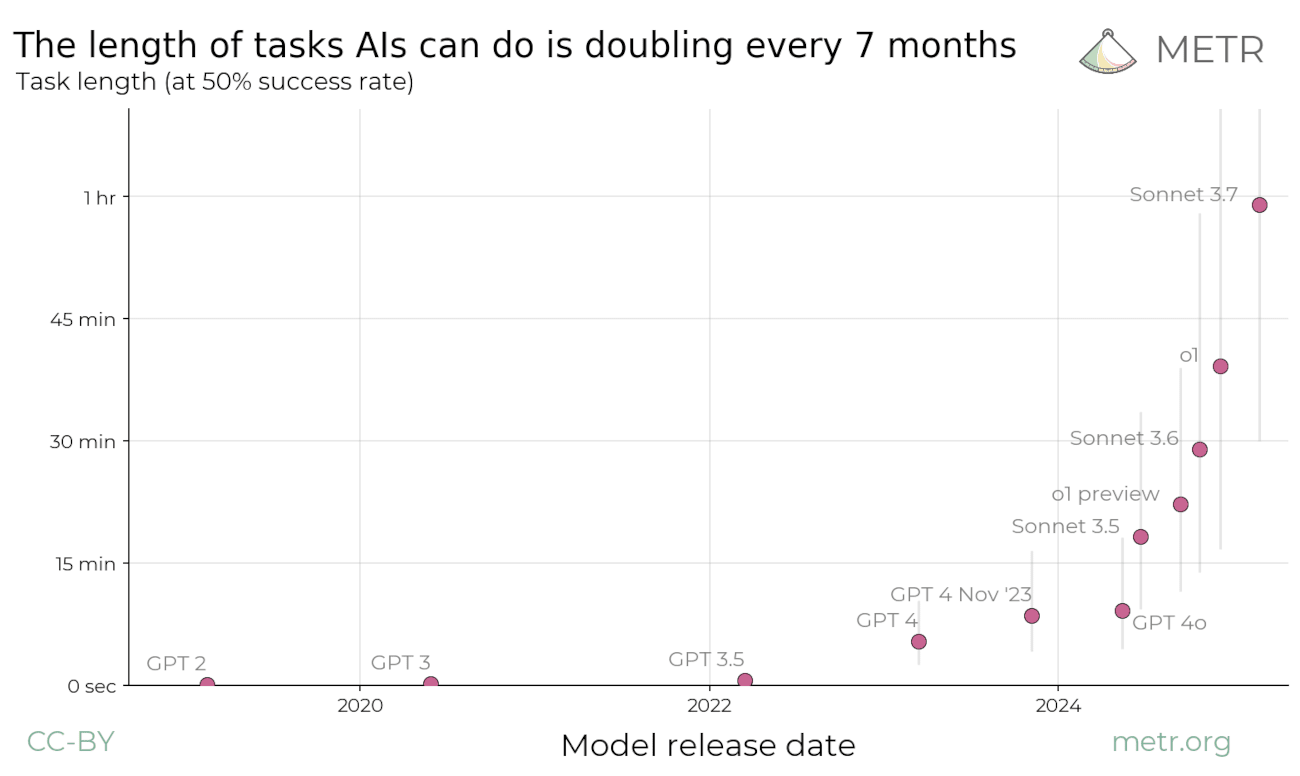
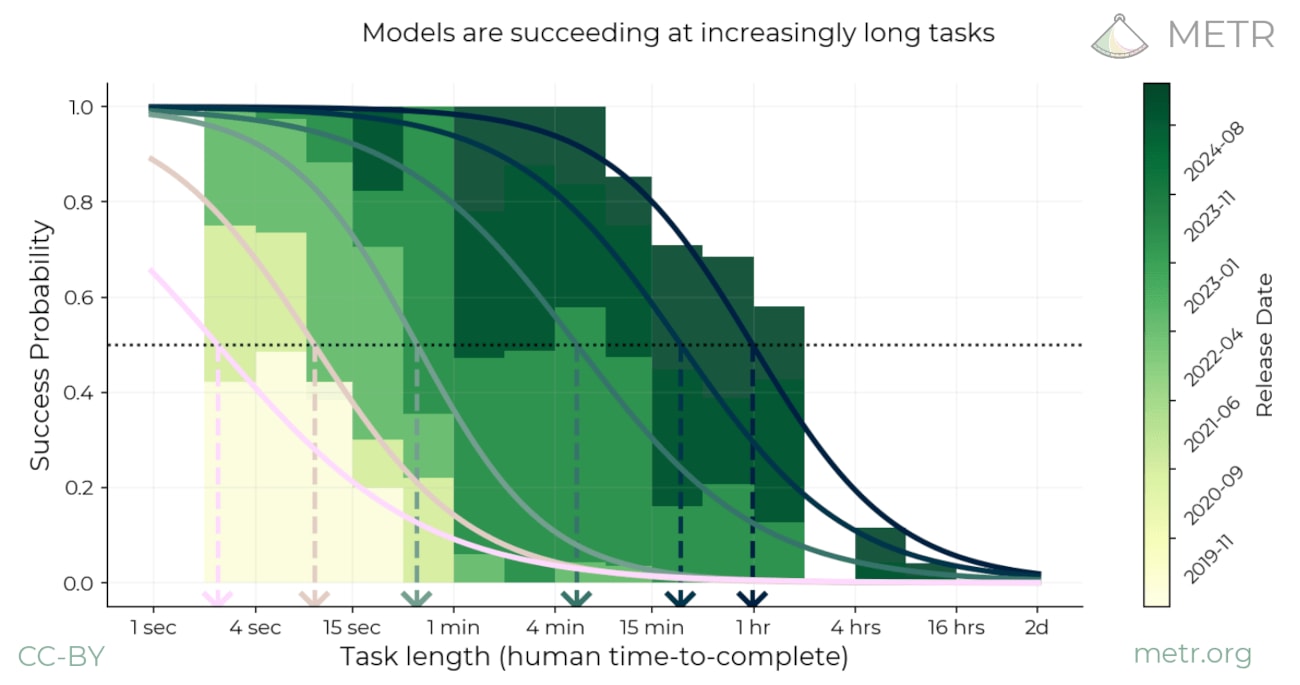
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
Full paper | Github repo
We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...]
---
Outline:
(08:58) Conclusion
(09:59) Want to contribute?
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
Full paper | Github repo
We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...]
---
Outline:
(08:58) Conclusion
(09:59) Want to contribute?
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
---
Narrated by TYPE III AUDIO.
---
704 episodi
Manage episode 475707851 series 3364760
Contenuto fornito da LessWrong. Tutti i contenuti dei podcast, inclusi episodi, grafica e descrizioni dei podcast, vengono caricati e forniti direttamente da LessWrong o dal partner della piattaforma podcast. Se ritieni che qualcuno stia utilizzando la tua opera protetta da copyright senza la tua autorizzazione, puoi seguire la procedura descritta qui https://it.player.fm/legal.
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
Full paper | Github repo
We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...]
---
Outline:
(08:58) Conclusion
(09:59) Want to contribute?
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
Full paper | Github repo
We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...]
---
Outline:
(08:58) Conclusion
(09:59) Want to contribute?
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
---
Narrated by TYPE III AUDIO.
---
704 episodi
Tutti gli episodi
×Benvenuto su Player FM!
Player FM ricerca sul web podcast di alta qualità che tu possa goderti adesso. È la migliore app di podcast e funziona su Android, iPhone e web. Registrati per sincronizzare le iscrizioni su tutti i tuoi dispositivi.
Simile a LessWrong (Curated & Popular)
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Redefining AI is a Three-Time Award-Winning Tech Podcast that cuts through the noise! Join Lauren Hawker Zafer, Chief Operating Officer at Squirro and Stevie Silver Award–winning creator, for a bold, thought-provoking exploration of artificial intelligence. Celebrated as intellectually rigorous, globally relevant, and truly unique, the show examines how AI shapes us socially, psychologically, and even physiologically. Each episode brings together leading academics, authors, executives, and i ...
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Audio home of The Jimquisition, featuring its lovely little podcast, Podquisition - starring Jim Sterling, Laura Kate, and Conrad Zimmerman!
…
continue reading
Investor Shayle Kann is asking big questions about how to decarbonize the planet: How cheap can clean energy get? Will artificial intelligence speed up climate solutions? Where is the smart money going into climate technologies? Every week on Catalyst, Shayle explains the world of climate tech with prominent experts, investors, researchers, and executives. Produced by Latitude Media.
…
continue reading
Player FM - App Podcast
Vai offline con l'app Player FM !
Vai offline con l'app Player FM !



